
四、内存管理
4.1 为什么要有虚拟内存?
Q:操作系统是如何管理虚拟地址与物理地址之间的关系?
主要有两种方式,分别是内存分段和内存分页,分段是比较早提出的。
Q:分段机制下,虚拟地址和物理地址是如何映射的?
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量。
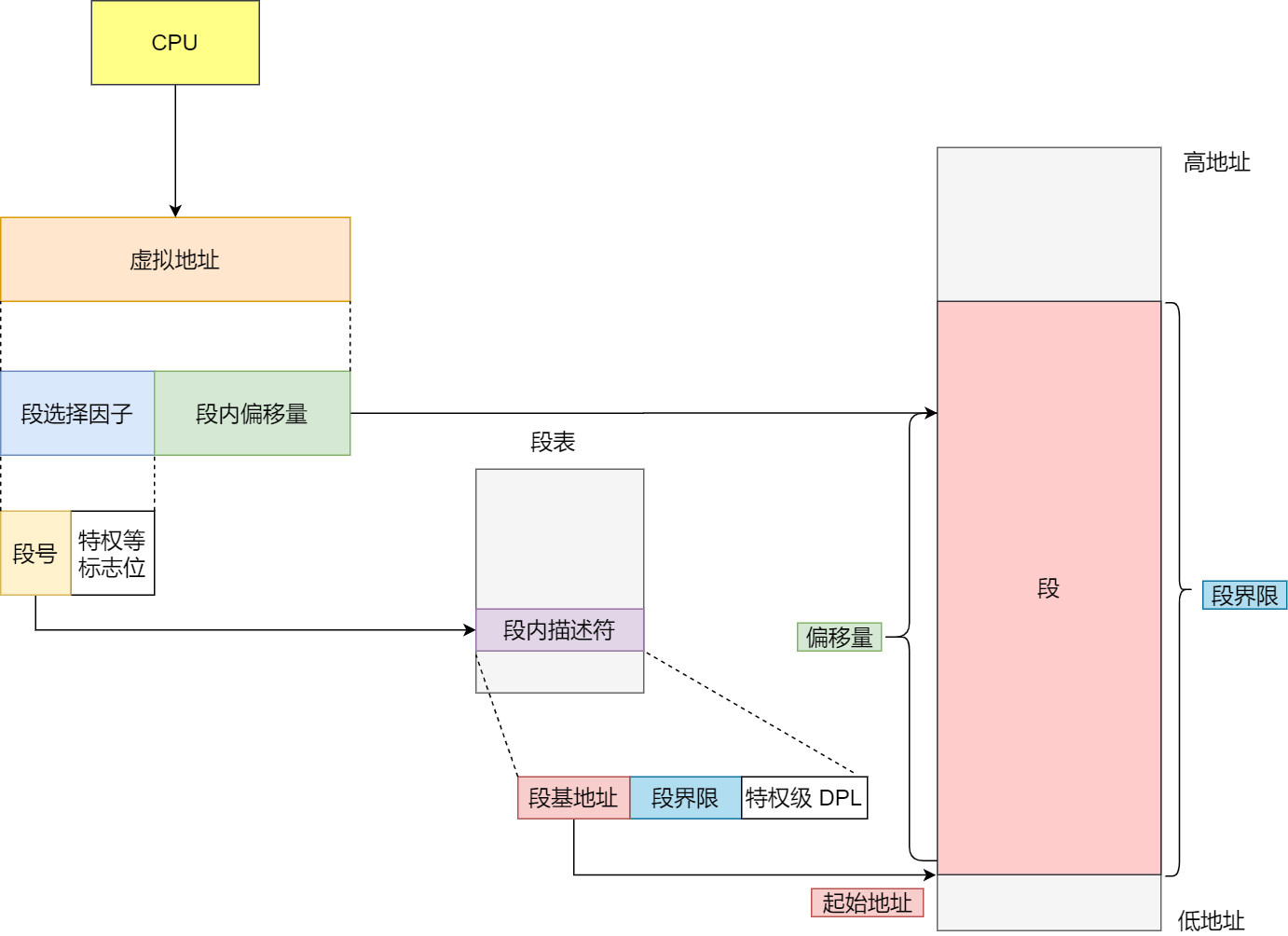
段选择因子和段内偏移量:
- 段选择子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
- 虚拟地址中的段内偏移量应该位于0和段界限之间,如果段内偏移量是合法的就将段基地址加上段内偏移量得到物理内存地址。
Q:分段为什么会产生内存碎片的问题?
内存碎片主要分为,内部内存碎片和外部内存碎片。
内存分段管理可以做到段根据实际需求分配内存,所以有多少需求就分配多大的段,所以不会出现内部内存碎片。
但是由于每个段的长度不固定,所以多个段未必能恰好使用所有的内存空间,会产生了多个不连续的小物理内存,导致新的程序无法被装载,所以会出现外部内存碎片的问题。 解决「外部内存碎片」的问题就是内存交换。
可以把音乐程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里。不过再读回的时候,我们不能装载回原来的位置,而是紧紧跟着那已经被占用了的 512MB 内存后面。这样就能空缺出连续的 256MB 空间,于是新的 200MB 程序就可以装载进来。
这个内存交换空间,在 Linux 系统里,也就是我们常看到的 Swap 空间,这块空间是从硬盘划分出来的,用于内存与硬盘的空间交换。
Q:再来看看,分段为什么会导致内存交换效率低的问题?
对于多进程的系统来说,用分段的方式,外部内存碎片是很容易产生的,产生了外部内存碎片,那不得不重新 5wap 内存区域,这个过程会产生性能瓶颈。
因为硬盘的访问速度要比内存慢太多了,每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。
所以,如果内存交换的时候,交换的是一个占内存空间很大的程序,这样整个机器都会显得卡顿。
为了解决内存分段的「外部内存碎片和内存交换效率低」的问题,就出现了内存分页。
Q:分页是怎么解决分段的「外部内存碎片和内存交换效率低」的问题?
内存分页由于内存空间都是预先划分好的,也就不会像内存分段一样,在段与段之间会产生间隙非常小的内存,这正是分段会产生外部内存碎片的原因。而采用了分页,页与页之间是紧密排列的,所以不会有外部碎片。 但是,因为内存分页机制分配内存的最小单位是一页,即使程序不足一页大小,我们最少只能分配一个页,所以页内会出现内存浪费,所以针对内存分页机制会有内部内存碎片的现象。 如果内存空间不够,操作系统会把其他正在运行的进程中的「最近没被使用」的内存页面给释放掉,也就是暂时写在硬盘上,称为换出(Swap Out)。一旦需要的时候,再加载进来,称为换入(SwapIn)。所以,一次性写入磁盘的也只有少数的-个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。
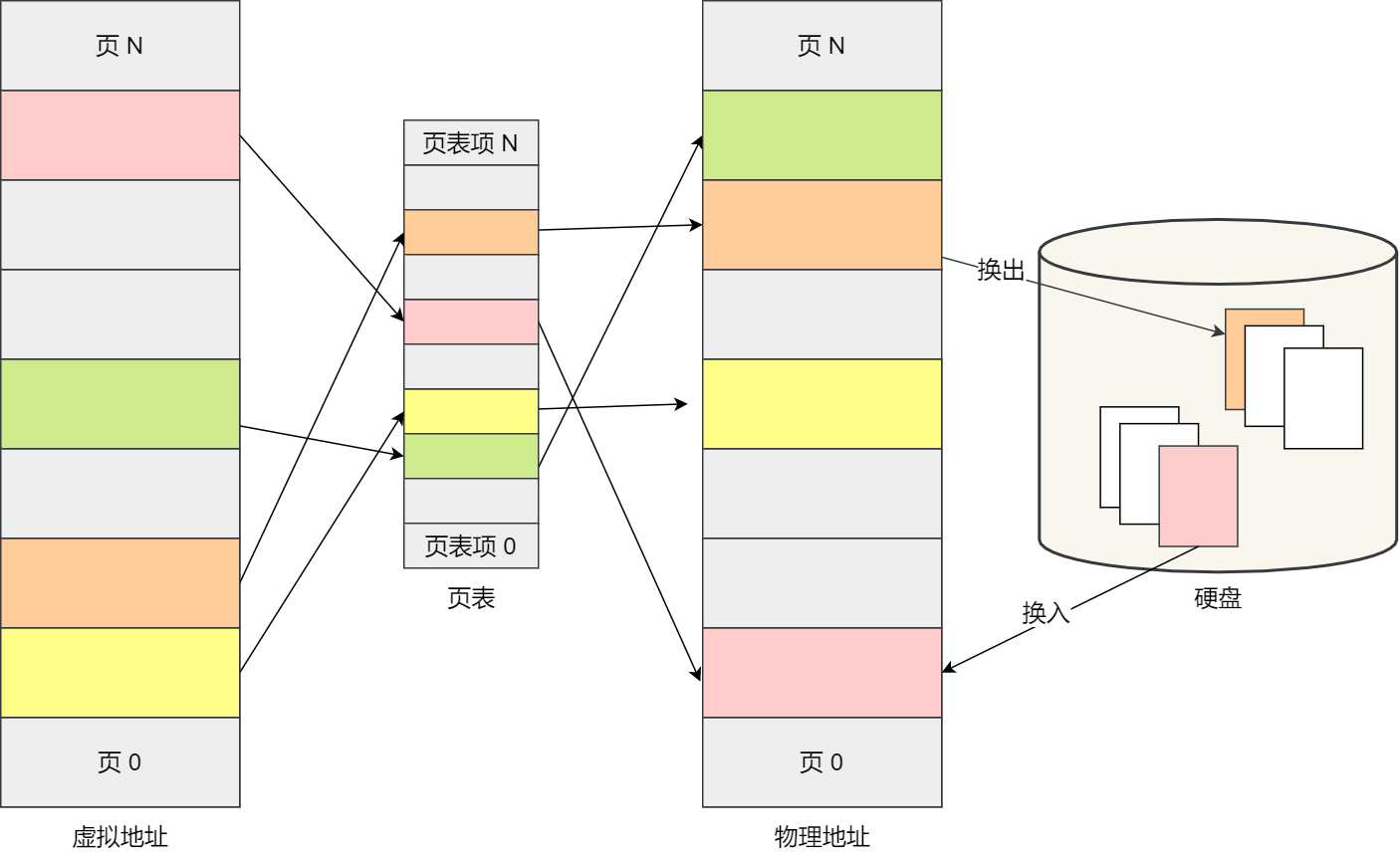
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
Q:分页机制下,虚拟地址和物理地址是如何映射的?
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址,见下图。
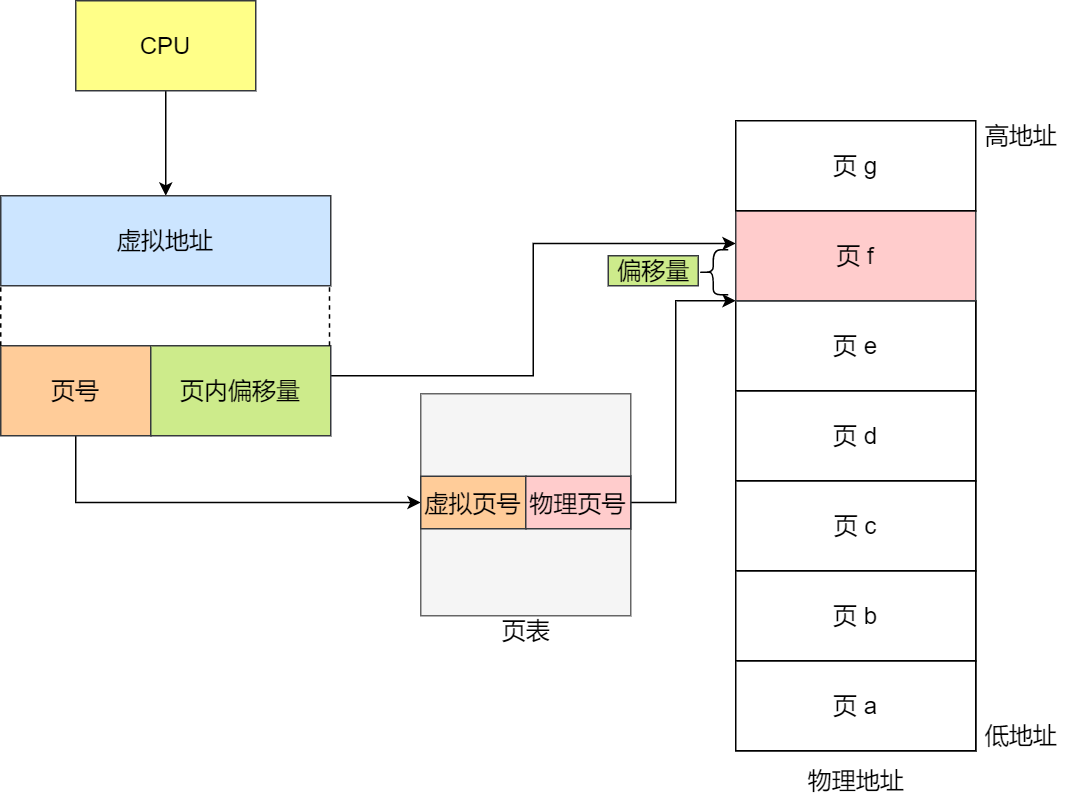
总结一下,对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量;
- 根据页号,从页表里面,查询对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
Q:简单的分页有什么缺陷吗?
有空间上的缺陷。
因为操作系统是可以同时运行非常多的进程的,那这不就意味着页表会非常的庞大。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12)那么就需要大约 100 万 (2^20)个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么, 108 个进程的话,就需要48BMB的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
要解决上面的问题,就需要采用一种叫作多级页表(Multi-Level Page Table)的解决方案。
Q:分了二级表,映射 4GB 地址空间就需要 4KB(一级页表)+4MB(二级页表)的内存,这样占用空间不是更大了吗?
当然如果 4GB 的虚拟地址全部都映射到了物理内存上的话,二级分页占用空间确实是更大了,但是,我们往往不会为一个进程分配那么多内存。
其实我们应该换个角度来看问题,还记得计算机组成原理里面无处不在的局部性原理么?
每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,因为会存在部分对应的页表项都是空的,根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20%的一级页表项被用到了,那么页表占用的内存空间就只有 4KB(一级页表)+20%*4MB(二级页表)=8.884M8,这对比单级页表的4M是不是一个巨大的节约?
那么为什么不分级的页表就做不到这样节约内存呢?
我们从页表的性质来看,保存在内存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部虚拟地址空间,不分级的页表就需要有 100 多万个页表项来映射,而二级分页则只需要 1024 个页表项(此时一级页表覆盖到了全部虚拟地址空间,二级页表在需要时创建)。
我们把二级分页再推广到多级页表,就会发现页表占用的内存空间更少了,这一切都要归功于对局部性原理的充分应用。
总结
为了在多进程环境下,使得进程之间的内存地址不受影响,相互隔离,于是操作系统就为每个进程独立分配一套虚拟地址空间,每个程序只关心自己的虚拟地址就可以,实际上大家的虚拟地址都是一样的,但分布到物理地址内存是不一样的。作为程序,也不用关心物理地址的事情。
每个进程都有自己的虚拟空间,而物理内存只有一个,所以当启用了大量的进程,物理内存必然会很紧张,于是操作系统会通过内存交换技术,把不常使用的内存暂时存放到硬盘(换出),在需要的时候再装载回物理内存(换入)。
那既然有了虚拟地址空间,那必然要把虚拟地址「映射」到物理地址,这个事情通常由操作系统来维护。
那么对于虚拟地址与物理地址的映射关系,可以有分段和分页的方式,同时两者结合都是可以的。
内存分段是根据程序的逻辑角度,分成了栈段、堆段、数据段、代码段等,这样可以分离出不同属性的段,同时是一块连续的空间。但是每个段的大小都不是统一的,这就会导致外部内存碎片和内存交换效率低的问题。
于是,就出现了内存分页,把虚拟空间和物理空间分成大小固定的页,如在 Linux系统中,每一页的大小为 4KB。由于分了页后,就不会产生细小的内存碎片,解决了内存分段的外部内存碎片问题。同时在内存交换的时候,写入硬盘也就一个页或几个页,这就大大提高了内存交换的效率。
再来,为了解决简单分页产生的页表过大的问题,就有了多级页表,它解决了空间上的问题,但这就会导致 CPU 在寻址的过程中,需要有很多层表参与,加大了时间上的开销。于是根据程序的局部性原理,在CPU 芯片中加入了TLB,负责缓存最近常被访问的页表项,大大提高了地址的转换速度。
Linux 系统主要采用了分页管理,但是由于Intel 处理器的发展史,Linux 系统无法避免分段管理。于是 Linux 就把所有段的基地址设为8,也就意味着所有程序的地址空间都是线性地址空间(虚拟地址),相当于屏蔽了CPU逻辑地址的概念,所以段只被用于访问控制和内存保护。
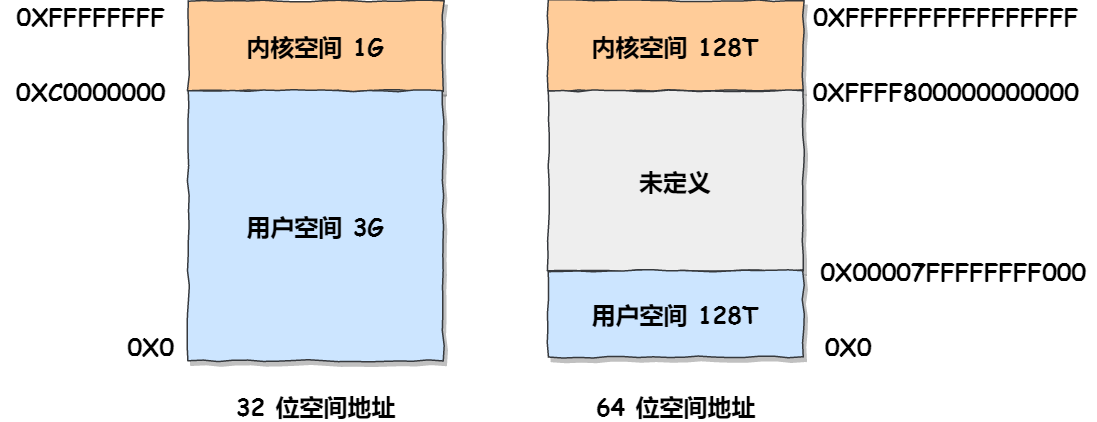
另外,Linux 系统中虚拟空间分布可分为用户态和内核态两部分,其中用户态的分布:代码段、全局变量、BSS、函数栈、堆内存、映射区。
最后,说下虚拟内存有什么作用?
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
4.2 malloc 是如何分配内存的?
实际上,malloc0 并不是系统调用,而是C库里的函数,用于动态分配内存。
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存。
- 方式一:通过 brk0 系统调用从堆分配内存
- 方式二:通过 mmap0 系统调用在文件映射区域分配内存;
方式一实现的方式很简单,就是通过 brk0 函数将「堆顶」指针向高地址移动,获得新的内存空间。如下图:

方式二通过 mmap0 系统调用中「私有匿名映射」的方式,在文件映射区分配一块内存,也就是从文件映射区“偷"了一块内存。如下图:

Q:什么场景下 malloc0 会通过 brk0 分配内存?又是什么场景下通过mmap0 分配内存?
malloc() 源码里默认定义了一个阈值!
- 如果用户分配的内存小于 128 KB,则通过 brk0 申请内存;
- 如果用户分配的内存大于 128 KB,则通过 mmap0 申请内存;
注意,不同的 glibc 版本定义的阈值也是不同的。
Q:malloc()分配的是物理内存吗?
不是的,malloc()分配的是虚拟内存。
如果分配后的虚拟内存没有被访问的话,虚拟内存是不会映射到物理内存的,这样就不会占用物理内存了。 只有在访问已分配的虚拟地址空间的时候,操作系统通过查找页表,发现虚拟内存对应的页没有在物理内存中,就会触发缺页中断,然后操作系统会建立虚拟内存和物理内存之间的映射关系。
Q:malloc(1)会分配多大的虚拟内存?
maloc() 在分配内存的时候,并不是老老实实按用户预期申请的字节数来分配内存空间大小,而是会预分配更大的空间作为内存池。
具体会预分配多大的空间,跟 malloc 使用的内存管理器有关系,我们就以 malloc默认的内存管理器(Ptmalloc2)来分析。
这个例子分配的内存小于 128 KB,所以是通过 brk0 系统调用向堆空间申请的内存,因此可以看到最右边有 [heap] 的标识。
可以看到,堆空间的内存地址范围是 00d73000-00d94000,这个范围大小是132KB,也就说明了 malloc(1)实际上预分配 132K 字节的内存,
Q:free 释放内存,会归还给操作系统吗?
通过 free 释放内存后,堆内存还是存在的,并没有归还给操作系统。
这是因为与其把这1字节释放给操作系统,不如先缓存着放进maloc 的内存池里当进程再次申请1字节的内存时就可以直接复用,这样速度快了很多。当然,当进程退出后,操作系统就会回收进程的所有资源。 上面说的 free 内存后堆内存还存在,是针对 malloc 通过 brk0 方式申请的内存的情况。
如果 malloc 通过 mmap 方式申请的内存,free 释放内存后就会归归还给操作系统。
对于「malloc 申请的内存,free 释放内存会归还给操作系统吗?」这个问题,我们可以做个总结了:
- malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
- malloc 通过 mmap() 方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
Q:为什么不全部使用 mmap 来分配内存?
咱们来聊聊 ma11oc 为啥不一股脑儿全用 mmap 来分内存,非得搞个 brkmmap 的组合拳。这事儿吧,说白了就是性能和资源管理上的一种权衡,没有一招鲜吃遍天的好事儿。
你想啊, mmap 确实挺酷的,每次都能从操作系统那儿划拉一块全新的、独立的虚拟内存区域给你,用完了直接munmap 还回去,干干净净,碎片问题也少。但问题就在于,这“酷"是有代价的!每次调用 mmap,都得劳烦操作系统内核跑一趟,做一大堆事情:找个没人用的地址空间、设置好页表项、可能还要清空内存页(确保安全)、更新内核数据结构.. 这一套流程下来,开销可比在用户态捣鼓点指针大多了。要是你程序里动不动就分配释放一堆小块儿内存(比如链表节点、小对象啥的),每次都来这么一趟mmap/munmap ,那性能可就真得慢得掉渣了,系统调用本身、TLB(快表)刷新的开销都能把你拖垮。
这时候 brk 的价值就体现出来了。它本质上是挪动一个叫“program break”的指针,把进程堆区的尾巴伸长或者缩短。分配小块内存时,ma11oc在用户空间自己管理堆区这块地盘就行了。它预先通过 brk扩大堆区(比如一次申请一大块),然后在这块连续的内存里,像切豆腐一样,根据你的请求切出合适的小块给你。释放的时候呢,也不是立刻还给操作系统,而是记录起来(放进空闲链表之类的结构),等下次有人再要小块内存时直接复用。只有当堆顶一大块连续内存都空闲了, ma11oc才可能用 brk把尾巴缩回去,把内存真正还给系统。这么搞,好处太明显了:对于大量、频繁的小内存申请释放,绝大部分操作都在用户态搞定,速度快得飞起,系统调用的开销被摊得非常薄。碎片问题虽然存在,但a11oc自己会努力合并相邻的空闲块来缓解。
当然, brk 也不是万金油。堆区是连续的,要是中间被零零碎碎的小块占着,即使总空闲空间够,也可能找不到一块连续的大空间来满足大内存申请(这就是内部碎片)。而且,堆区理论上只能向一个方向长(通常向上),管理起来没那么灵活。
所以,malloc的智慧就在于“看人下菜碟”:
- 小内存、频繁请求:主要靠 brk 管理的堆区。用户态搞定,速度快如闪电。
- 大内存(通常超过一个阈值,比如几百KB):直接用单独映射一块。这mmap样避免了在堆区造成难以忍受的大洞(外部碎片),释放时也能干净利落地立刻归还给系统,不拖累堆区。
总结起来就是:灵活干净但开销大,brk管理堆速度快但对大块和碎片敏mmap感。 ma11oc 混着用,让小内存分配享受 brk的速度红利,让大内存分配享受mmap 的独立与干净,各取所长,才能在各种内存分配需求下都交出比较均衡、高效的答卷。
要是全用 mmap ,小内存分配的频繁开销会让程序慢得怀疑人生,要是全用brk,遇上大内存或者长期运行产生大量碎片,程序可能就“卡死"在明明有内存却分配不出来的尴尬境地。所以,这个组合拳,打得有理!
Q:既然 brk 那么牛逼,为什么不全部使用 brk 来分配?
前面我们提到通过 brk 从堆空间分配的内存,并不会归还给操作系统。
因此,随着系统频繁地 malloc 和 free ,尤其对于小块内存,堆内将产生越来越多不可用的碎片,导致“内存泄露”。而这种“泄露"现象使用 valgrind(内测泄漏检测工具) 是无法检测出来的。 所以,malloc 实现中,充分考虑了 brk和 mmap 行为上的差异及优缺点,默认分配大块内存(128KB) 才使用 mmap 分配内存空间。
Q:free() 函数只传入一个内存地址,为什么能知道要释放多大的内存?
还记得,我前面提到,malloc 返回给用户态的内存起始地址比进程的堆空间起始地址多了 16 字节吗?
这个多出来的 16 字节就是保存了该内存块的描述信息,比如有该内存块的大小。
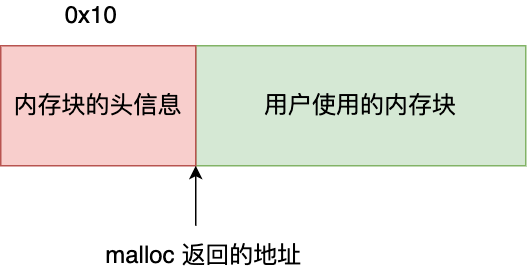
这样当执行 free0 函数时,free 会对传入进来的内存地址向左偏移 16 字节,然后从这个 16 字节的分析出当前的内存块的大小,自然就知道要释放多大的内存了。
Q:malloc内存分配器是怎样实现的?
面试官:malloc内存分配器是怎样实现的?
4.3 内存满了,会发生什么?
Q:虚拟内存有什么作用?
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
Q:内存分配的过程是怎样的?
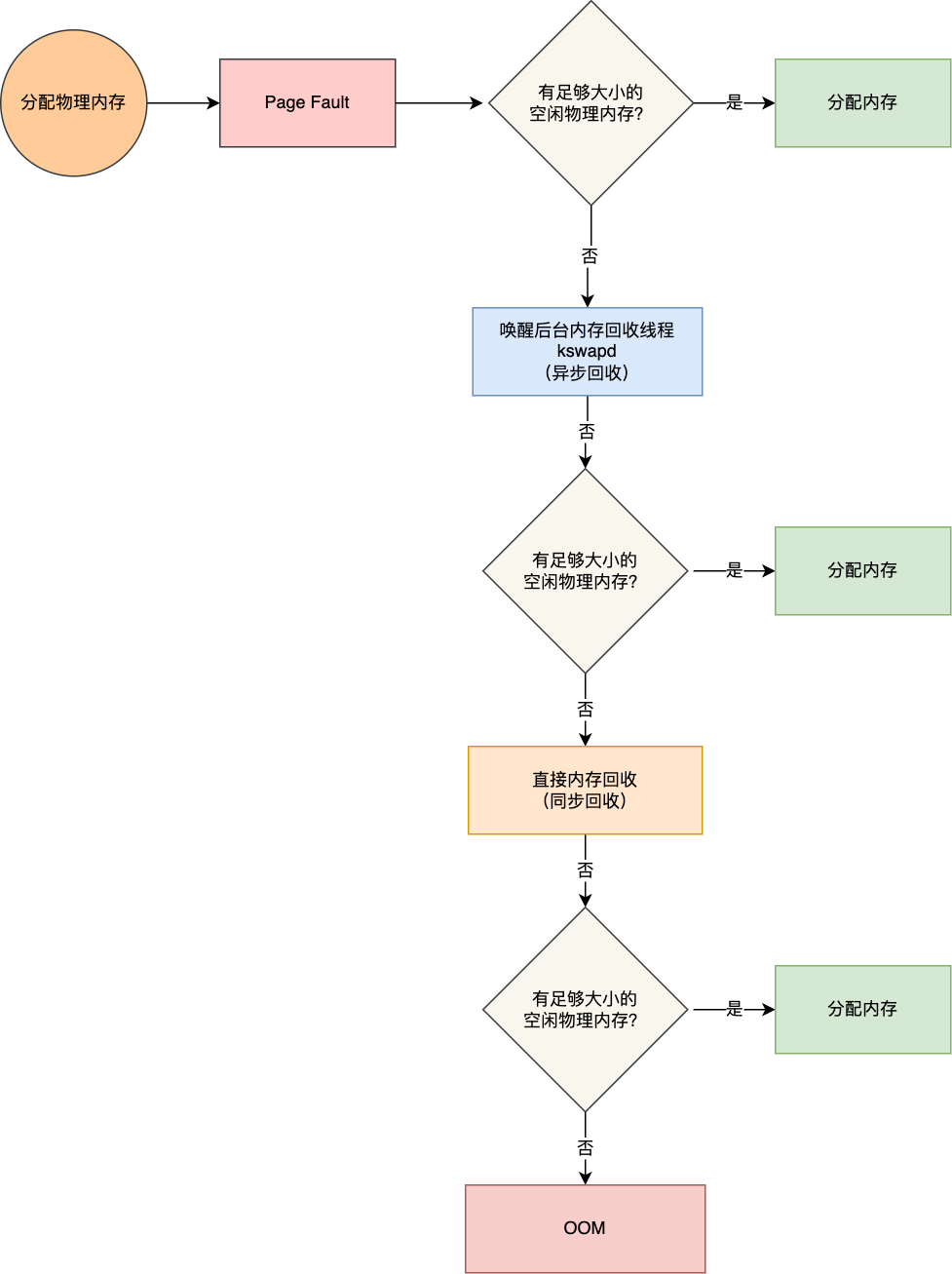
应用程序通过 maloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存,这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page FaultHandler(缺页中断函数)处理。 缺页中断处理函数会看是否有空闲的物理内存,如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。 如果没有空闲的物理内存,那么内核就会开始进行回收内存的工作,回收的方式主要是两种:直接内存回收和后台内存回收。
- 后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
如果直接内存回收后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了触发 OOM (out of Memory)机制。 OOM Killer 机制会根据算法选择一个占用物理内存较高的进程,然后将其杀死,以便释放内存资源,如果物理内存依然不足,OOM Kier 会继续杀死占用物理内存较高的进程,直到释放足够的内存位置。
Q:哪些内存可以被回收?
系统内存紧张的时候,就会进行回收内存的工作,那具体哪些内存是可以被回收的呢?
主要有两类内存可以被回收,而且它们的回收方式也不同。
- 文件页(File-backed Page):内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)都叫作文件页。大部分文件页,都可以直接释放内存,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。所以,回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存。- 匿名页(Anonymous Page):这部分内存没有实际载体,不像文件缓存有硬盘文件这样一个载体,比如堆、栈数据等。这部分内存很可能还要再次被访问,所以不能直接释放内存,它们回收的方式是通 过Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。LRU 回收算法,实际上维护着 active 和 inactive 两个双向链表,其中:
- active list 活跃内存页链表,这里存放的是最近被访问过(活跃)的内存页;
- inactive list 不活跃内存页链表,这里存放的是很少被访问(非活跃)的内存页; 越接近链表尾部,就表示内存页越不常访问。这样,在回收内存时,系统就可以根据活跃程度,优先回收不活跃的内存。
Q:回收内存带来的性能影响?
在前面我们知道了回收内存有两种方式。
- 一种是后台内存回收,也就是唤醒 kswapd 内核线程,这种方式是异步回收的,不会阻塞进程。
- 一种是直接内存回收,这种方式是同步回收的,会阻塞进程,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起系统负荷高。 可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 //0 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。 可以看到,回收内存的操作基本都会发生磁盘 /0 的,如果回收内存的操作很频繁,意味着磁盘 1/0 次数会很多,这个过程势必会影响系统的性能,整个系统给人的感觉就是很卡。
Q:下面针对回收内存导致的性能影响,说说常见的解决方式?
- 调整文件页和匿名页的回收倾向 从文件页和匿名页的回收操作来看,文件页的回收操作对系统的影响相比匿名页的回收操作会少一点,因为文件页对于干净页回收是不会发生磁盘 !/0 的,而匿名页的 Swap 换入换出这两个操作都会发生磁盘I/O.
Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整文件页和匿名页的回收倾向。 swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
一般建议 swappiness 设置为0(默认值是 60),这样在回收内存的时候,会更倾向于文件页的回收,但是并不代表不会回收匿名页。
- 尽早触发 kswapd 内核线程异步回收内存
我们可以使用 sar -81 命令来观察:

图中红色框住的就是后台内存回收和直接内存回收的指标,它们分别表示:
- pgscank/s:kswapd(后台回收线程)每秒扫描的 page 个数。
- pgscand/s: 应用程序在内存申请过程中每秒直接扫描的 page 个数。
- pgsteal/s: 扫描的 page 中每秒被回收的个数(pgscank+pgscand)。 如果系统时不时发生抖动,并且在抖动的时间段里如果通过 sar -8 观察到 pgscand 数值很大,那大概率是因为「直接内存回收」导致的。 针对这个问题,解决的办法就是,可以通过尽早的触发「后台内存回收」来避免应用程序进行直接内存回收。
Q:什么条件下才能触发 kswapd 内核线程回收内存呢?
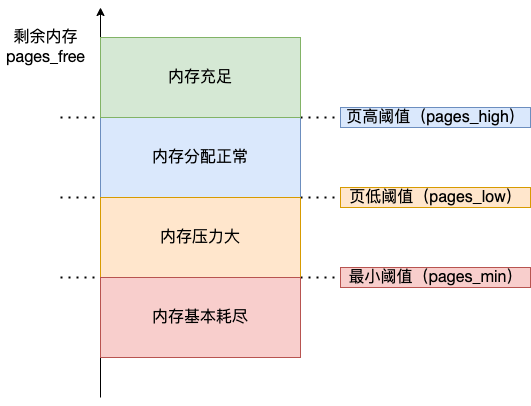
内核定义了三个内存阈值(watermark,也称为水位),用来衡量当前剩余内存(pages_free)是否充裕或者紧张,分别是: 页最小阈值(pages_min); 页低阈值(pages_low); 页高阈值(pages_high); 这三个内存阈值会划分为四种内存使用情况,如下图:
kswapd 会定期扫描内存的使用情况,根据剩余内存(pages_free)的情况来进行内存回收的工作。
- 图中绿色部分:如果剩余内存(pages_free)大于 页高阈值(pages_high),说明剩余内存是充足的;中匳威外办的孩撓閾掣坷浏究
- 图中蓝色部分:如果剩余内存(pages_free)在页高阈值(pages_high)和页低阈值(pages_low)之间,说明内存有一定压力,但还可以满足应用程序申请内存的请求;
- 图中橙色部分:如果剩余内存(pages_free)在页低值(pages_low)和页最小值(pages_min)之间,说明内存压力比较大,剩余内存不多了。这时kswapd0 会执行内存回收,直到剩余内存大于高阈值(pages_high)为止。虽然会触发内存回收,但是不会阻塞应用程序,因为两者关系是异步的。
- 图中红色部分:如果剩余内存(pages_free)小于页最小闽值(pages_min),说明用户可用内存都耗尽了,此时就会触发直接内存回收,这时应用程序就会被阻塞,因为两者关系是同步的。
可以看到,当剩余内存页(pages_free)小于页低阈值(pages_ow),就会触发 kswapd 进行后台回收,然后 kswapd 会一直回收到剩余内存页(pages_free)大于页高阈值(pages _high)。 也就是说 kswapd 的活动空间只有 pages low 与 pages min 之间的这段区域,如果剩余内存低于了 pages_min 会触发直接内存回收,高于了 pages high 又不会唤醒 kswapd。页低阈值(pages low)可以通过内核选项 /proc/sys/vm/min_free_kbytes(该参数代表系统所保留空闲内存的最低限)来间接设置。 min_free_kbytes 虽然设置的是页最小阈值(pages_min),但是页高阈值(pages_high)和页低阈值(pages_ow)都是根据页最小阈值(pages_min)计算生成的,它们之间的计算关系如下:
pages min = min free kbytes
pages low= pages min*5/4
pages high = pages min*3/2如果系统时不时发生抖动,并且通过 sar -8 观察到 pgscand 数值很大,那大概率是因为直接内存回收导致的,这时可以增大 min _free_kbytes 这个配置选项来及早地触发后台回收,然后继续观察 pgscand 是否会降为 0。
增大了 min free kbytes 配置后,这会使得系统预留过多的空闲内存,从而在一定程度上降低了应用程序可使用的内存量,这在一定程度上浪费了内存。极端情况下设置 min free kbvtes 接近实际物理内存大小时,留给应用程序的内存就会太少而可能会频繁地导致 OOM 的发生。
所以在调整 min_free_kbytes 之前,需要先思考一下,应用程序更加关注什么,如果关注延迟那就适当地增大 min_free_kbytes,如果关注内存的使用量那就适当地调小 min_free_kbytes。
Q:什么是 NUMA 架构?
SMP 指的是一种多个CPU 处理器共享资源的电脑硬件架构,也就是说每个 CPU 地位平等,它们共享相同的物理资源,包括总线、内存、10、操作系统等。每个CPU 访问内存所用时间都是相同的,因此,这种系统也被称为一致存储访问结构(UMA,Uniform Memory Access)。
随着 CPU 处理器核数的增多,多个CPU 都通过一个总线访问内存,这样总线的带宽压力会越来越大,同时每个 CPU 可用带宽会减少,这也就是 SMP 架构的问题。
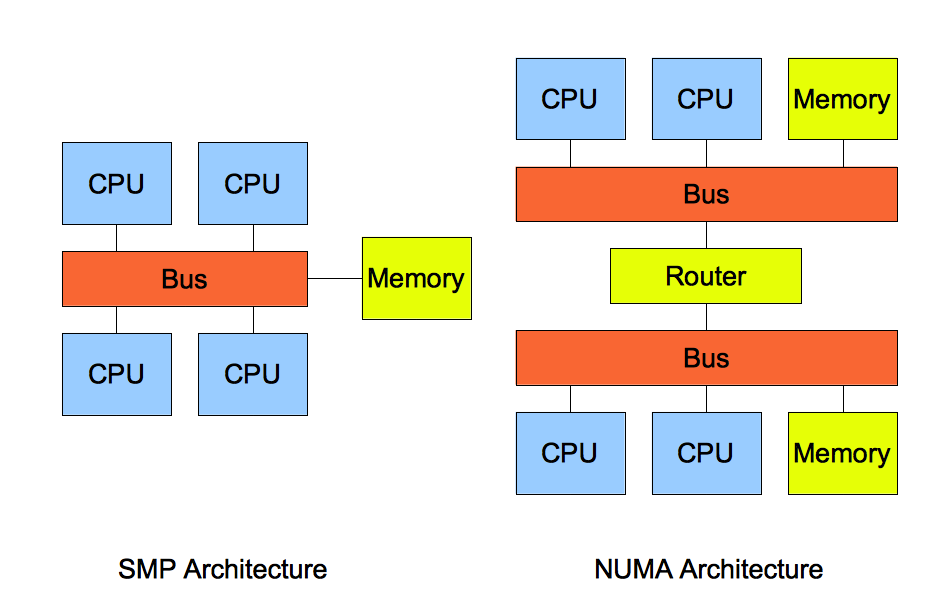
为了解决 SMP 架构的问题,就研制出了 NUMA 结构,即非一致存储访问结构(Non-uniform memoryaccess,NUMA)。
NUMA 架构将每个 CPU 进行了分组,每一组 CPU 用 Node 来表示,一个 Node 可能包含多个 CPU 。
每个 Node 有自己独立的资源,包括内存、10 等,每个 Node 之间可以通过互联模块总线(QPI)进行通信,所以,也就意味着每个 Node 上的 CPU 都可以访问到整个系统中的所有内存。但是,访问远端 Node的内存比访问本地内存要耗时很多。
Q:NUMA 架构跟回收内存有什么关系?
在 NUMA 架构下,当某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。 具体选哪种模式,可以通过 /proc/sys/vm/zone_reclaim_mode 来控制。它支持以下几个选项
- 0(默认值):在回收本地内存之前,在其他Node 寻找空闲内存;
- 1:只回收本地内存;
- 2:只回收本地内存,在本地回收内存时,可以将文件页中的脏页写回硬盘,以回收内存。
- 4:只回收本地内存,在本地回收内存时,可以用 swap 方式回收内存。 在使用 NUMA 架构的服务器,如果系统出现还有一半内存的时候,却发现系统频繁触发「直接内存回收」,导致了影响了系统性能,那么大概率是因为 zone_reclaim mode 没有设置为0,导致当本地内存不足的时候,只选择回收本地内存的方式,而不去使用其他 Node 的空闲内存。 虽然说访问远端 Node 的内存比访问本地内存要耗时很多,但是相比内存回收的危害而言,访问远端Node 的内存带来的性能影响还是比较小的。因此,zone_reclaim_mode 一般建议设置为 0。
Q:如何保护一个进程不被 OOM 杀掉呢?
在系统空闲内存不足的情况,进程申请了一个很大的内存,如果直接内存回收都无法回收出足够大的空闲内存,那么就会触发 OOM 机制,内核就会根据算法选择一个进程杀掉。 Linux 到底是根据什么标准来选择被杀的进程呢?这就要提到一个在 Linux内核里有一个 oom badness()函数,它会把系统中可以被杀掉的进程扫描一遍,并对每个进程打分,得分最高的进程就会被首先杀掉。 进程得分的结果受下面这两个方面影响: 第一,进程已经使用的物理内存页面数。 第二,每个进程的 OOM 校准值 oom_score_adj。它是可以通过 /proc/[pid]/oom_score_adj 来配置的。我们可以在设置 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kil 的几率。 函数 oom badness0) 里的最终计算方法是这样的:
// points 代表打分的结果
//process_pages 代表进程已经使用的物理内存页面数
//oom score adj 代表 00M 校准值
//totalpages 代表系统总的可用页面数
points =process pages + oom score adj*totalpages/1000用「系统总的可用页面数」乘以「OOM 校准值 oom_score_adj」再除以 1000,最后再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Ki 的几率也就越大。 每个进程的 oom_score_adj默认值都为 0,所以最终得分跟进程自身消耗的内存有关,消耗的内存越大越容易被杀掉。我们可以通过调整 oom_score_adj 的数值,来改成进程的得分结果:
- 如果你不想某个进程被首先杀掉,那你可以调整该进程的oom_score_adj,从而改变这个进程的得分结果,降低该进程被 OOM 杀死的概率。
- 如果你想某个进程无论如何都不能被杀掉,那你可以将 oom_score_adj 配置为 -1000。 我们最好将一些很重要的系统服务的 oom_score_adj配置为 -1000,比如 sshd,因为这些系统服务一旦被杀掉,我们就很难再登陆进系统了。 但是,不建议将我们自己的业务程序的 oom_score_adi 设置为 -1000,因为业务程序一旦发生了内存泄漏,而它又不能被杀掉,这就会导致随着它的内存开销变大,OOM kiler 不停地被唤醒,从而把其他进程一个个给杀掉。
总结
内核在给应用程序分配物理内存的时候,如果空闲物理内存不够,那么就会进行内存回收的工作,主要有两种方式:
- 后台内存回收:在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异. 步的,不会阻塞进程的执行。
- 直接内存回收:如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。 可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/0 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。回收内存的操作基本都会发生磁盘 I/0 的,如果回收内存的操作很频繁,意味着磁盘 V0 次数会很多,这个过程势必会影响系统的性能。
针对回收内存导致的性能影响,常见的解决方式。
- 设置 /proc/sys/vm/swappiness,调整文件页和匿名页的回收倾向,尽量倾向于回收文件页;
- 设置 /proc/sys/vm/min_free_kbytes,调整 kswapd 内核线程异步回收内存的时机;
- 设置 /proc/sys/vm/zone_reclaim_mode,调整 NUMA 架构下内存回收策略,建议设置为 0,这样在回收本地内存之前,会在其他 Node 寻找空闲内存,从而避免在系统还有很多空闲内存的情况下,因本地Node 的本地内存不足,发生频繁直接内存回收导致性能下降的问题;
在经历完直接内存回收后,空闲的物理内存大小依然不够,那么就会触发 OOM 机制,OOM killer 就会根据每个进程的内存占用情况和 oom_score_adj 的值进行打分,得分最高的进程就会被首先杀掉。
我们可以通过调整进程的 /proc/[pid]/oom_score_adj 值,来降低被 OOM kiler 杀掉的概率。
4.4 在 4GB 物理内存的机器上,申请 8G 内存会怎么样?
Q:在 32 位操作系统、4GB 物理内存的机器上,申请 8GB 内存,会怎么样?
因为 32 位操作系统,进程最多只能申请3G8 大小的虚拟内存空间,所以进程申请8GB 内存的话,在申请虚拟内存阶段就会失败(我手上没有 32 位操作系统测试,我估计失败的错误是 cannot allocatememory,也就是无法申请内存失败)。
Q:在 64 位操作系统、4GB 物理内存的机器上,申请 8G 内存,会怎么样?
64 位操作系统,进程可以使用 128 TB 大小的虚拟内存空间,所以进程申请 8GB 内存是没问题的,因为进程申请内存是申请虚拟内存,只要不读写这个虚拟内存,操作系统就不会分配物理内存。
Q:那么将这个 overcommit_memory 设置为1之后,64 位的主机就可以申请接近 128T 虚拟内存了吗?
Linux 中的 overcommit_memory 参数
可以使用 cat /proc/sys/vm/overcommit_memory 来查看这个参数,这个参数接受三个值:
- 如果值为0(默认值),代表:Heuristic overcommit handling,它允许overcommit,但过于明目张胆的overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存。Heuristic的意思是“试探式的”,内核利用某种算法猜测你的内存申请是否合理,大概可以理解为单次申请不能超过freememory+ free swap+pagecache的大小+SLAB中可回收的部分,超过了就会拒绝overcommit。
- 如果值为 1,代表:Always overcommit,允许overcommit,对内存申请来者不拒。
- 如果值为 2,代表:Don'tovercommit.禁止overcommit。
不一定,还得看你服务器的物理内存大小。
读者的服务器物理内存是2GB,实验后发现,进程还没有申请到 128T虚拟内存的时候就被杀死了。
注意,这次是 killed,而不是 Cannot Allocate Memory,说明并不是内存申请有问题,而是触发 OOM了。
但是为什么会触发 OOM 呢?
那得看你的主机的「物理内存」够不够大了,即使 maloc 申请的是虚拟内存,只要不去访问就不会映射到物理内存,但是申请虚拟内存的过程中,还是使用到了物理内存(比如内核保存虚拟内存的数据结构,也是占用物理内存的),如果你的主机是只有 2GB 的物理内存的话,大概率会触发 OOM。
直到直接内存回收之后,也无法回收出一块空间供这个进程使用,这个时候就会触发 OOM,给所有能杀死的进程打分,分数越高的进程越容易被杀死。
在这里当然是这个进程得分最高,那么操作系统就会将这个进程杀死,所以最后会出现 kied,而不是Cannot allocate memoryo
Q:那么 2GB 的物理内存的 64 位操作系统,就不能申请128T的虚拟内存了吗?
其实可以,上面的情况是还没开启 swap 的情况。
Q:Swap 机制的作用
前面讨论在 32 位/64 位操作系统环境下,申请的虚拟内存超过物理内存后会怎么样?
在 32 位操作系统,因为进程最大只能申请3GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
在 64 位操作系统,因为进程最大只能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G内存也是没问题,因为申请的内存是虚拟内存。
程序申请的虚拟内存,如果没有被使用,它是不会占用物理空间的。当访问这块虚拟内存后,操作系统才会进行物理内存分配。
如果申请物理内存大小超过了空闲物理内存大小,就要看操作系统有没有开启 Swap 机制:
如果没有开启 Swap 机制,程序就会直接 OOM;
如果有开启 Swap 机制,程序可以正常运行。
Q:什么是 Swap 机制?
当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到磁盘,等到那些程序要运行时,再从磁盘中恢复保存的数据到内存中。
另外,当内存使用存在压力的时候,会开始触发内存回收行为,会把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
这种,将内存数据换出磁盘,又从磁盘中恢复数据到内存的过程,就是 Swap 机制负责的。
Swap 就是把一块磁盘空间或者本地文件,当成内存来使用,它包含换出和换入两个过程
- 换出(Swap Out),是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存;
- 换入(Swap In),是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来;
Swap 换入换出的过程如下图:
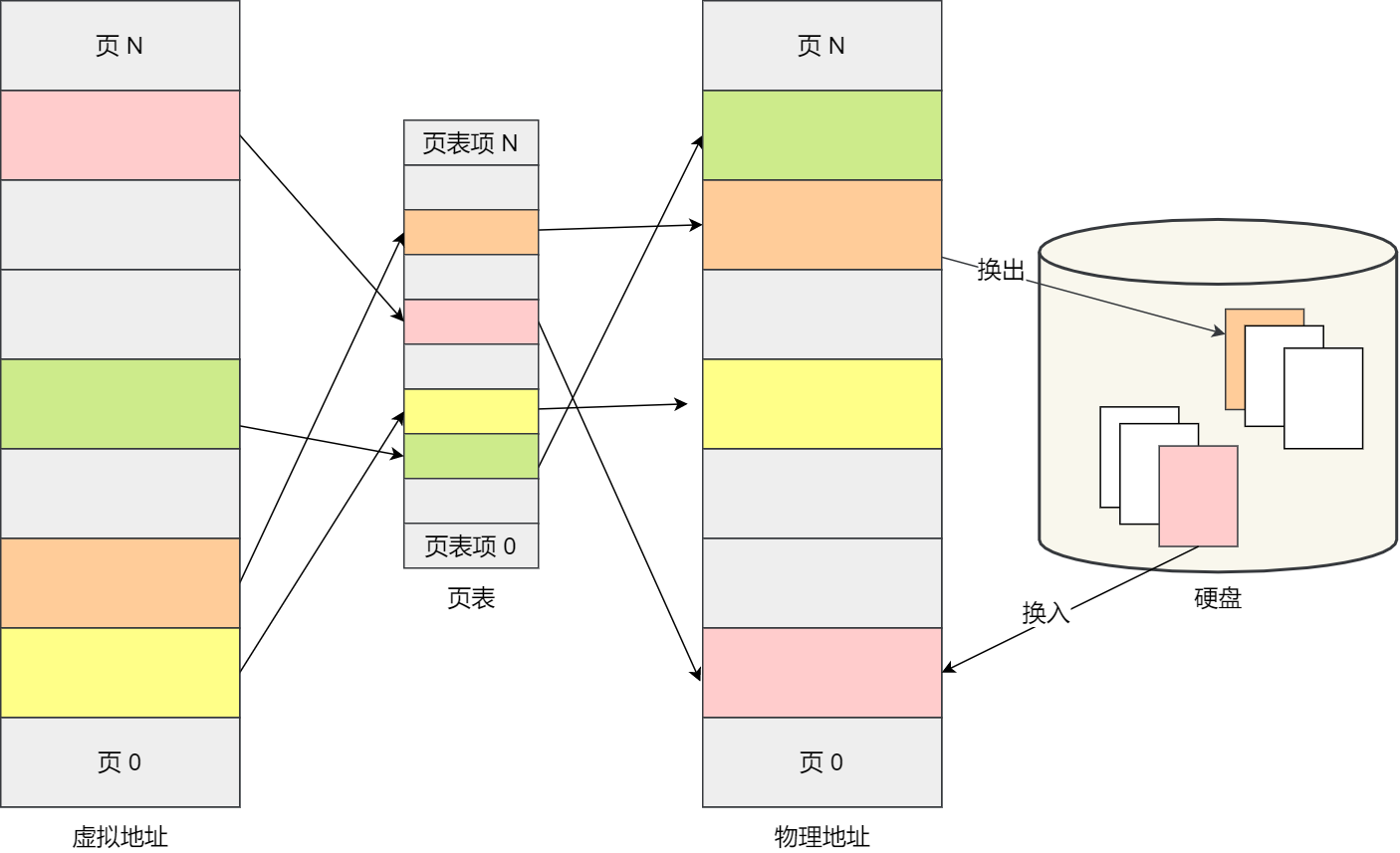
使用 Swap 机制优点是,应用程序实际可以使用的内存空间将远远超过系统的物理内存。由于硬盘空间的价格远比内存要低,因此这种方式无疑是经济实惠的。当然,频繁地读写硬盘,会显著降低操作系统的运行速率,这也是 Swap 的弊端。
Linux 中的 Swap 机制会在内存不足和内存闲置的场景下触发:
- 内存不足:当系统需要的内存超过了可用的物理内存时,内核会将内存中不常使用的内存页交换到磁盘上为当前进程让出内存,保证正在执行的进程的可用性,这个内存回收的过程是强制的直接内存回收(Direct Page Reclaim)。直接内存回收是同步的过程,会阻塞当前申请内存的进程。
- 内存闲置:应用程序在启动阶段使用的大量内存在启动后往往都不会使用,通过后台运行的守护进程(kSwapd),我们可以将这部分只使用一次的内存交换到磁盘上为其他内存的申请预留空间。kswapd是 Linux 负责页面置换(Page replacement)的守护进程,它也是负责交换闲置内存的主要进程,它会在空闲内存低于一定水位区 时,回收内存页中的空闲内存保证系统中的其他进程可以尽快获得申请的内存。kswapd 是后台进程,所以回收内存的过程是异步的,不会阻塞当前申请内存的进程。
Linux 提供了两种不同的方法启用 Swap,分别是 Swap 分区(Swap Partition)和 Swap 文件(Swapfile),开启方法可以看这个资料口:
- Swap 分区是硬盘上的独立区域,该区域只会用于交换分区,其他的文件不能存储在该区域上,我们可以使用 swapon -s命令查看当前系统上的交换分区;
- Swap 文件是文件系统中的特殊文件,它与文件系统中的其他文件也没有太多的区别;
Q:Swap 换入换出的是什么类型的内存?
内核缓存的文件数据,因为都有对应的磁盘文件,所以在回收文件数据的时候,直接写回到对应的文件就可以了。
但是像进程的堆、栈数据等,它们是没有实际载体,这部分内存被称为匿名页。而且这部分内存很可能还要再次被访问,所以不能直接释放内存,于是就需要有一个能保存匿名页的磁盘载体,这个载体就是Swap 分区。
匿名页回收的方式是通过 Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
Q:什么是 OOM?
内存溢出(0ut Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出。
总结
简单总结下:
- 在 32 位操作系统,因为进程理论上最大能申请3GB 大小的虚拟内存,所以直接申请8G 内存,会申请失败。
- 在 64位 位操作系统,因为进程理论上最大能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有Swap 分区:
- 如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是OOM(内存溢出);
- 如果有 Swap 分区,即使物理内存只有 4GB,程序也能正常使用 8GB 的内存,进程可以正常运行;。
4.5 如何避免预读失效和缓存污染的问题?
Q:传统 LRU 是如何管理内存数据的?
LRU 算法一般是用「链表」作为数据结构来实现的,链表头部的数据是最近使用的,而链表末尾的数据是最久没被使用的。那么,当空间不够了,就淘汰最久没被使用的节点,也就是链表末尾的数据,从而腾出内存空间。
因为 Linux 的 Page Cache 和 MySQL 的 Buffer Pool 缓存的基本数据单位都是页(Page)单位,所以后续以「页」名称代替「数据」。
传统的 LRU 算法的实现思路是这样的:
- 当访问的页在内存里,就直接把该页对应的 LRU 链表节点移动到链表的头部。
- 当访问的页不在内存里,除了要把该页放入到 LRU 链表的头部,还要淘汰 LRU 链表末尾的页。
传统的 LRU 算法并没有被 Linux 和 MySQL 使用,因为传统的 LRU 算法无法避免下面这两个问题:
- 预读失效导致缓存命中率下降;
- 缓存污染导致缓存命中率下降;
Q:什么是预读机制?
Linux 操作系统为基于 Page Cache 的读缓存机制提供预读机制,一个例子是:
- 应用程序只想读取磁盘上文件 A 的 offset 为 0-3KB 范围内的数据,由于磁盘的基本读写单位为 block(4KB),于是操作系统至少会读 0-4KB 的内容,这恰好可以在一个 page 中装下。
- 但是操作系统出于空间局部性原理(靠近当前被访问数据的数据,在未来很大概率会被访问到),会选择将磁盘块 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加载到内存,于是额外在内存中申请了 3 个 page;
Q:预读失效会带来什么问题?
如果这些被提前加载进来的页,并没有被访问,相当于这个预读工作是白做了,这个就是预读失效。
如果使用传统的 LRU 算法,就会把「预读页」放到 LRU 链表头部,而当内存空间不够的时候,还需要把末尾的页淘汰掉。
如果这些「预读页」如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率 。
Q:如何避免预读失效造成的影响?
我们不能因为害怕预读失效,而将预读机制去掉,大部分情况下,空间局部性原理还是成立的。
要避免预读失效带来影响,最好就是让预读页停留在内存里的时间要尽可能的短,让真正被访问的页才移动到 LRU 链表的头部,从而保证真正被读取的热数据留在内存里的时间尽可能长。
那到底怎么才能避免呢?
Linux 操作系统和 MySQL Innodb 通过改进传统 LRU 链表来避免预读失效带来的影响,具体的改进分别如下:
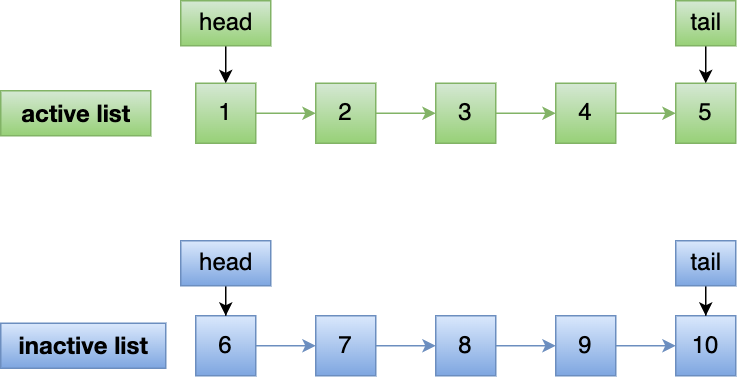
- Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list);
- MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。 这两个改进方式,设计思想都是类似的,都是将数据分为了冷数据和热数据,然后分别进行 LRU 算法。不再像传统的 LRU 算法那样,所有数据都只用一个 LRU 算法管理。
Q:Linux 是如何避免预读失效带来的影响?
Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list)。
- active list 活跃内存页链表,这里存放的是最近被访问过(活跃)的内存页;
- inactive list 不活跃内存页链表,这里存放的是很少被访问(非活跃)的内存页;
有了这两个 LRU 链表后,预读页就只需要加入到 inactive list 区域的头部,当页被真正访问的时候,才将页插入 active list 的头部。如果预读的页一直没有被访问,就会从 inactive list 移除,这样就不会影响 active list 中的热点数据。
Q:MySQL 是如何避免预读失效带来的影响?
MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域,young 区域 和 old 区域。
young 区域在 LRU 链表的前半部分,old 区域则是在后半部分,这两个区域都有各自的头和尾节点,如下图:
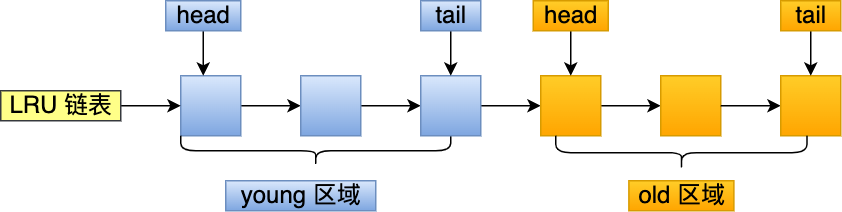
young 区域与 old 区域在 LRU 链表中的占比关系并不是一比一的关系,而是 63:37(默认比例)的关系。
划分这两个区域后,预读的页就只需要加入到 old 区域的头部,当页被真正访问的时候,才将页插入 young 区域的头部。如果预读的页一直没有被访问,就会从 old 区域移除,这样就不会影响 young 区域中的热点数据。
Q:什么是缓存污染?
虽然 Linux (实现两个 LRU 链表)和 MySQL (划分两个区域)通过改进传统的 LRU 数据结构,避免了预读失效带来的影响。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
当我们在批量读取数据的时候,由于数据被访问了一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
Q:缓存污染会带来什么问题?
缓存污染带来的影响就是很致命的,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 I/O,系统性能就会急剧下降。
我以 MySQL 举例子,Linux 发生缓存污染的现象也是类似。
当某一个 SQL 语句扫描了大量的数据时,在 Buffer Pool 空间比较有限的情况下,可能会将 Buffer Pool 里的所有页都替换出去,导致大量热数据被淘汰了,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 I/O,MySQL 性能就会急剧下降。
注意, 缓存污染并不只是查询语句查询出了大量的数据才出现的问题,即使查询出来的结果集很小,也会造成缓存污染。
Q:怎么避免缓存污染造成的影响?
前面的 LRU 算法只要数据被访问一次,就将数据加入活跃 LRU 链表(或者 young 区域),这种 LRU 算法进入活跃 LRU 链表的门槛太低了!正式因为门槛太低,才导致在发生缓存污染的时候,很容就将原本在活跃 LRU 链表里的热点数据淘汰了。
所以,只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉。
Linux 操作系统和 MySQL Innodb 存储引擎分别是这样提高门槛的:
- Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
- MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
- 如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;
- 如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域; 提高了进入活跃 LRU 链表(或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
在批量读取数据时候,如果这些大量数据只会被访问一次,那么它们就不会进入到活跃 LRU 链表(或者 young 区域),也就不会把热点数据淘汰,只会待在非活跃 LRU 链表(或者 old 区域)中,后续很快也会被淘汰。
总结
传统的 LRU 算法法无法避免下面这两个问题:
- 预读失效导致缓存命中率下降;
- 缓存污染导致缓存命中率下降;
为了避免「预读失效」造成的影响,Linux 和 MySQL 对传统的 LRU 链表做了改进:
- Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active list)和非活跃 LRU 链表(inactive list)。
- MySQL Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。 但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
为了避免「缓存污染」造成的影响,Linux 操作系统和 MySQL Innodb 存储引擎分别提高了升级为热点数据的门槛:
- Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
- MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
- 如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;
- 如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域; 通过提高了进入 active list (或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。